Новый алгоритм Яндекса — «Снежинск» и «Жадный алгоритм» ранжирования
Суть алгоритма, который получил название Greedy algorithm (Жадный алгоритм), состоит в следующем: алгоритм разбивается на этапы. На каждом этапе алгоритм старается максимально приблизиться к заданной цели, без «взгляда» в будущее. Предполагается, что максимально приближаясь к назначенной цели на каждом этапе, мы достигаем назначенную цель оптимальным образом.
Основное утверждение такого алгоритма, что цель достигается оптимальным способом, конечно не всегда верно. Рассмотрим подтверждающий пример:
Цель: выдать сдачу в магазине минимальным числом монет.
Переменные: монеты достоинством 6, 5 и 1 единица.
Конкретизация цели: выдать 10 денежных единиц.
Выполнение этапов алгоритма:
- Берём максимальное число монет достоинством 6 единиц (т.е 1 штуку)
- Берём максимальное число монет достоинством 5 единиц (т.е 0 штук)
- Берём недостающее число монет достоинством 1 единица (т.е 4 штуки)
Итог: выдано 5 монет, в то время как оптимальное решение, две монеты достоинство 5 единиц каждая.
Замечание: в действующих на сегодняшний момент реальных монетных системах Greedy algorithm приводит к оптимальному результату.
Применимость жадного алгоритма для решения оптимизационной задачи
К оптимизационной задаче может быть применен принцип жадного выбора, только в том случае, если последовательное выполнение всех локальных этапов даёт глобально оптимальное решение поставленной задачи. Доказать применимость такого алгоритма оптимизации, можно по методу математической индукции, если в применении в рассматриваемому алгоритму проходит следующая цепочка рассуждений: а) удаётся доказать, что выполнение первого этапа Жадного алгоритма не закрывает путь к достижению оптимального решения (т.е. не сужает множество оптимальных решений) (это база индукции). б) Показывается аналогичность полученной на 2-ом этапе задачи и начальной задачи (это индукционный переход). в) Доказательство завершается по индукции.
Этот алгоритм положен в основу ранжирование документов в поисковой системе Яндекс, версия от 17.11.2009 и носит название «Снежинск».
Применение древовидного алгоритма для определения самой ранжирующей функции
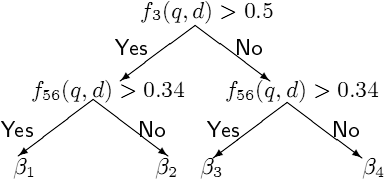 Новая формула ранжирования, как-бы неизвестна до момента задания запроса пользователем. Что это значит? Это значит, что для одного запроса — одна функция, для другого — другая. Это в теории, а на практике программирования такая задача сводится к заданию древовидной структуры определения каждого следующего слагаемого в формуле в зависимости от ответа на «контрольный вопрос» на предыдущем. То есть, всё как в тесте в журнале за 5 рублей — ответили «да», тогда идите налево, а коли ответили «нет», тогда направо (см. иллюстрирующую диаграмму справа).
Новая формула ранжирования, как-бы неизвестна до момента задания запроса пользователем. Что это значит? Это значит, что для одного запроса — одна функция, для другого — другая. Это в теории, а на практике программирования такая задача сводится к заданию древовидной структуры определения каждого следующего слагаемого в формуле в зависимости от ответа на «контрольный вопрос» на предыдущем. То есть, всё как в тесте в журнале за 5 рублей — ответили «да», тогда идите налево, а коли ответили «нет», тогда направо (см. иллюстрирующую диаграмму справа).
Хождение по ячейкам теста имеет определенное число шагов, это число может варьироваться в зависимости от запроса пользователя, типа документа и ещё множества факторов.
Что можно констатировать с уверенностью? Весь процесс стал сильно нелинейным и возможно, что для каждого отдельного запроса, теперь необходим свой уникальный подход к поисковому продвижению, а многие старые и надежные схемы перестают «работать», скажем для коммерческих высокочастотных запросов. Ответ на вопрос об изменении качестве поиска в лучшую (или худшую) сторону — остаётся открытым.